
发展
1-of-N Encoding
Word Class
Word Embedding
一个词在不同句子里意思不一样怎么办?
Contextualized Word Embedding
- Each word token has its own embadding(even though it has the same word type).
- The embeddings of word tokens also depend on its context.
ELMO - Embeddings from Language Model
上下文词嵌入(Contextual Word Embeddings)技术
一个词的嵌入表示不应该是一个固定的向量,而应该根据它所在的上下文句子动态变化
ELMo的核心是一个双向语言模型(BiLM),它通过在大规模语料库上训练这个模型来获得词的嵌入
- 前向语言模型:从一个句子的开头到结尾进行阅读,根据前面的词预测下一个词
- 后向语言模型:从一个句子的结尾到开头进行“倒着”阅读,根据后面的词预测前一个词
ELMo使用多层双向长短期记忆网络(BiLSTM) 作为其语言模型的架构
每一层LSTM都会对输入的词生成一个隐藏状态(向量表示)
低层的LSTM更多地捕捉句法信息(如词性标注)。
高层的LSTM更多地捕捉语义信息(如一词多义)。
生成ELMo词向量(关键步骤)
- 对于一个句子中的某个词(例如 “银行”),ELMo的最终向量表示是它所有层(包括初始嵌入层)的隐藏状态的加权组合
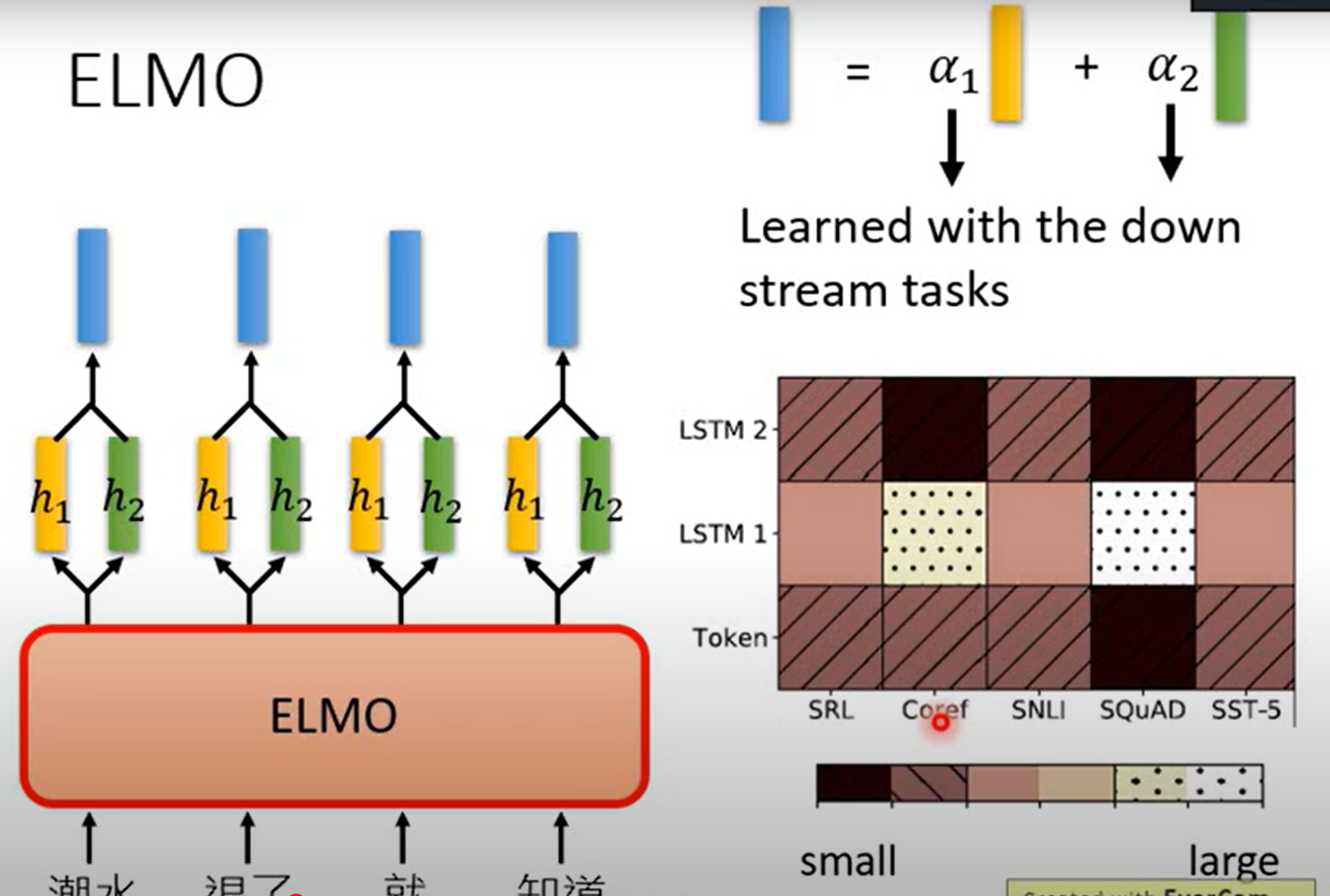
- 对于一个句子中的某个词(例如 “银行”),ELMo的最终向量表示是它所有层(包括初始嵌入层)的隐藏状态的加权组合
Bert- Bidirectional Encoder Representations from Transformers
- BERT完全基于Transformer模型中的编码器(Encoder)部分构建,使用了12层Transformer编码器堆叠而成,形成了非常深的模型结构
- 它不再使用传统的“根据上文预测下一个词”的语言模型任务,而是设计了两个新颖的无监督任务:掩码语言模型(Masked Language Model, MLM)、下一句预测(Next Sentence Prediction, NSP)
- MLM:整个句子包含被mask的词输入到bert模型中,bert在12个transformer encoder学习到丰富的上下文信息之后会输出整个句子每个词的向量,当然包括被mask的词,此时这个被mask掉的词向量已经包含了非常丰富的上下文信息,把这个输出的mask的词向量送入一个分类层,先进行线性变换得到适合分类表形状大小的向量,然后送入softmax进行归一化得到每个token的可能性,也就是概率,到此为止,被mask的词就可以被预测出来。
- NSP:NSP任务的核心目标是:让模型学会理解两个句子之间的关系。首先创建正负样本各一半一半作为bert的输入,正样本就是语料库(如维基百科)中随机选取一个连续的文本段落,负样本就是从语料库中随机选取一个连续的文本段落,句子A是该段落中的一句话,句子B是从整个语料库中随机抽取的任意一句话,它与句子A在语义上完全无关。输入BERT的Transformer编码器序列的最终形式:[CLS] + 句子A + [SEP] + 句子B + [SEP],模型处理完整个序列后,会输出序列中每个位置对应的上下文向量。取出 [CLS] 标签对应的输出向量(记为 C)。我们认为这个向量已经编码了整个输入序列的聚合信息,尤其适合做分类判断。将向量 C 送入一个分类层(一个简单的全连接层+Softmax),该层将 C 映射为一个2维的概率分布,分别对应 IsNext 和 NotNext 的概率。但是存在问题:任务过于简单,负样本质量不高。
- [SEP]:the boundary of two sentences
- [CLS]:the position that outputs classification results
How to use BERT?
- 情感分析:判断一条影评是“正面”还是“负面”
- 自然语言推理:判断一个“假设”句子是否可以从“前提”句子中推断出来
- 命名实体识别:识别句子中的人名、地名、组织机构名等实体
- 抽取式问答:从给定的段落中找出答案的起止位置,这是BERT的招牌应用之一 。。。
BERT处理不同任务时,每一层的重要性
https://arxiv.org/pdf/1905.05950
GPT-Generative Pre-Training
参数量巨大
- ELMO 94M
- BERT 340M
- GPT 1542M
在没有训练资料的情况下,就可以
- Reading Comprehension
- Summarization
- Translation
GPT2模型结构
- GPT-2完全由堆叠的Transformer Decoder 块构成。但需要注意的是,它只使用了原始Transformer中Decoder的一部分,具体来说是移除了编码器-解码器注意力层的Decoder
- GPT-2模型就是将这些完全相同的Transformer Decoder块一个一个堆叠起来
- GPT-2 Small: 12层
- GPT-2 Medium: 24层
- GPT-2 Large: 36层
- GPT-2 XL: 48层 层数越多,模型的表示能力和学习能力就越强