
https://arxiv.org/abs/1706.03762
https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=61
来自李宏毅老师的讲解
RNN和CNN为啥不行
- RNN处理序列时,每个时间步的输出(或者隐藏状态)都依赖于上一个时间步的隐藏状态和输出,训练RNN时须通过BPTT(随时间反向传播)算法更新参数,所以RNN难以实现平行化
- 用CNN来代替RNN,CNN是可以实现平行化的,因为我不需要b1算完,我就可以计算b2,只要我堆叠足够的卷积核,就可以捕捉到整个序列的信息,但是缺点是我需要叠很多层😭
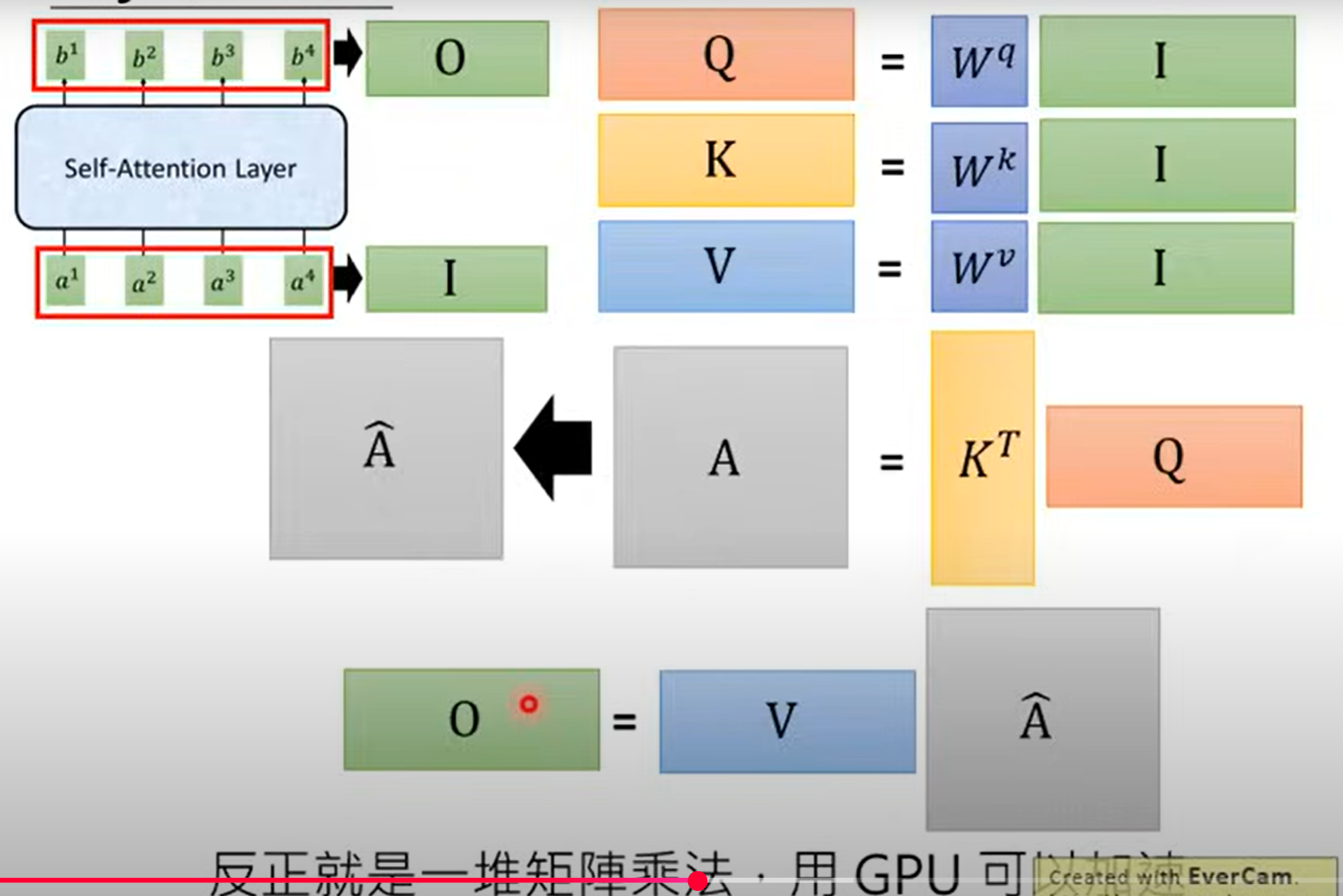
Self-Attention
- 首先是一个词的原始向量分别乘以对应的权重矩阵得到自己的Q、K、V,然后整个squence的q矩阵去点积K矩阵,经过Softmax归一化后得到一个矩阵就是A,这个A相当于是每个词之间的联系的强弱,接着去和V矩阵做矩阵乘法得到B矩阵,所以说现在b1、b2、b3...可以平行地被算出来
- 别忘了一开始还会有Positional Encoding加进去
Multi-head Self-attention
下面是来自bilibili一位up主的讲解做的笔记
https://www.bilibili.com/video/BV1xoJwzDESD/?spm_id_from=333.337.search-card.all.click
Seq2seq with Attetion
什么是seqtoseq? https://blog.csdn.net/zhx111111111/article/details/119788265
google曾用seq2seq模型加attention模型来实现了翻译功能,类似的还可以实现聊天机器人对话模型
经典的rnn模型固定了输入序列和输出序列的大小,而seq2seq模型则突破了该限制