
目标检测常见算法
1.传统的目标检测算法
核心流程:
1.区域选择(穷举策略,使用不同大小的滑动窗口对图像进行遍历,时间复杂度很高) 2.特征提取 常用的包括:
- HOG 方向梯度直方图 计算图像局部区域中梯度方向的分布统计直方图,并将其组合成一个长的特征向量
- Haar-like特征 通过计算图像中相邻矩形区域的像素和之差来表示特征
- SIFT/SURF 3.分类器分类 常用的包括:
- SVM 支持向量机:寻找一个最优的超平面,能够最大化不同类别特征向量直接的间隔
- AdaBoost 自适应增强 将多个弱分类器组合成一个强分类器
2.候选区域 + 深度学习分类 Two-Stage
首先找出图像中可能包含物体的候选区域(Region Proposal),然后利用深度卷积神经网络(CNN)对这些候选区域进行精细的分类和位置微调。
R-CNN系列 核心流程
1.生成候选区域 目标:替代传统的滑动窗口,用更高效、更准确的方式生成可能包含物体的区域。这些区域的数量通常控制在1k-2k个,远少于滑动窗口,且召回率高。(召回率关注漏检问题,精确率关注误检问题,二者之间存在一种权衡)
- 早期方法(如R-CNN, SPPnet):使用选择性搜索(Selective Search) 等传统算法。原理:基于图像的颜色、纹理、大小和形状等特征,将相似的相邻区域逐步合并,生成各种尺度的候选区域。
- 进化方法(如Faster R-CNN):引入区域提议网络(Region Proposal Network, RPN),这是一个革命性的改进。原理:RPN是一个小的神经网络,直接在CNN提取的特征图上滑动,自动判断每个位置是否有物体(前景/背景)并预测出候选框的粗略位置。这使得候选区域的生成过程也变成了端到端的学习,速度极快。 2.对候选区域进行分类和位置精修
- 特征提取:R-CNN:将每个候选区域缩放(扭曲) 成固定大小(如227x227),然后分别送入CNN中提取特征。缺点:重复计算极其严重,因为成千上万个候选区域之间有大量重叠部分;SPPnet 和 Fast R-CNN:革命性改进! 只对整张图像进行一次CNN特征提取,得到一个共享的特征图。然后,将每个候选区域映射到这张特征图上,对应截取出一个小的特征块。为了解决特征块大小不一的问题,SPPnet使用了空间金字塔池化(SPP),Fast R-CNN使用了更简单的RoI池化(RoI Pooling),将它们转化为固定尺寸的特征向量。
- 分类与回归:将固定大小的特征向量输入到后续的全连接层中。两个并列的输出头:分类器:输出每个候选区域属于各个类别(包括“背景”类)的概率。边界框回归器:对候选区域的边界框坐标(x, y, w, h)进行微调,使其更精确地包围目标。
- 后处理:非极大值抑制(NMS):与传统方法一样,在第二阶段之后,可能会对同一个物体产生多个重叠的、得分不同的检测框。NMS用于去除冗余框,只保留每个物体最可信的一个检测结果。
3.基于深度学习的回归方法 One-Stage
- 摒弃了“生成候选区域”这一独立步骤,直接将目标检测任务视为一个端到端的回归(Regression)问题
YOLO系列
SSD
- 在多尺度的特征图上进行预测。不仅在最深的特征图上预测,也会在较浅的特征图上进行预测。浅层特征图分辨率高,利于检测小物体;深层特征图语义信息强,利于检测大物体。
RetinaNet
- 图像中大部分区域是背景,只有少部分区域有目标。导致在训练时,容易分类的背景样本贡献了大部分损失,淹没了难以分类的正样本的声音,使模型优化方向偏离。解决方案:提出了 Focal Loss 损失函数。通过降低容易样本的权重,让模型更加专注于训练那些难以分类的样本。
YOLO系列
YOLOv1
- 原文:https://arxiv.org/pdf/1506.02640
- 参考:https://blog.csdn.net/weixin_43334693/article/details/129011644https://blog.csdn.net/xu1129005165/article/details/132540581
- 本文将检测变为一个regression problem(回归问题),YOLO 从输入的图像,仅仅经过一个神经网络,直接得到一些bounding box以及每个bounding box所属类别的概率。因为整个的检测过程仅仅有一个网络,所以它可以直接进行end-to-end的优化。
优点:
- 速度快
- 在整个图像上推断
- 可以学习到目标的泛化表征,泛化能力高 但精度不高,尤其对于小物体
Unified Detection
- YOLO将输入图像划分为S*S的栅格,每个栅格负责检测中心落在该栅格中的物体。yolov1中S=7,B=2。
- 每一个栅格预测B个bounding boxes,以及这些bounding boxes的confidence scores。这个 confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准。公式定义如下:如果这个栅格中不存在一个object,则confidencescore应该为0。否则的话,confidence score则为predicted bounding box与 ground truth box之间的交并比IOU(intersection over union)。 YOLO对每个bounding box有5个predictions:x, y, w, h, and confidence。 坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。 坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。 confidence就是预测的bounding box和ground truth box的IOU值。 每一个栅格还要预测C个conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。整个yolo算法的流程如图2.
Network Design

- 包含24个卷积层和2个全连接层
- 1×1卷积层的存在是为了跨通道信息整合
Train
- 预训练:首先利用ImageNet 1000-class的分类任务数据集Pretrain卷积层。使用上述网络中的前20个卷积层,加上一个average-pooling layer,最后加一个全连接层,作为 Pretrain 的网络。
- 模型微调:在预训练模型基础上添加4个卷积层和2个全连接层,同时为了获取更精细化的结果,将输入图像的分辨率由 224* 224 提升到 448* 448。
- 归一化:将x,y,w,h归一化到[0,1]区间
- 激活函数:最后的全连接层采用线性激活函数,其他层均使用Leaky RELU函数
- 损失函数:边界框损失(Bounding box loss)、置信度损失(confidence loss)和分类损失(classification loss),其中置信度损失又可以细分为包含目标的Bbox的置信度损失和未包含目标的Bbox的置信度损失两种。最后的输出形状是7730


Inference
- Yolov1网络输入是448x448的图像,输出是7x7x30的张量。每张图片分成49个grid cell,每个grid cell预测2个Bounding box,整个推理过程会产生98个检测框。
- 多数情况下,模型能够清晰的判断目标中心位置位于哪个grid cell,然后仅用一个Bounding box预测目标位置。
- 对于较大或者位于多个网格边界的目标物,可能会被多个网格同时较好地定位,此时则采用非极大值抑制NMS的方法,去除冗余,即对于同一目标物只保留置信度(这里等于IoU)最大的Bounding box。训练阶段不需要NMS。
过程
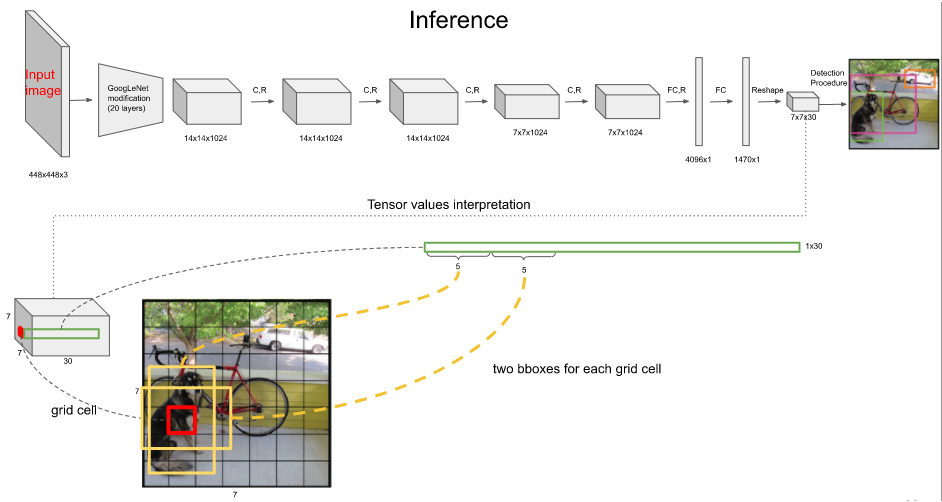
- 每个grid cell包含两个bbox和20个class类别的条件概率,每个bbox包含x,y,w,h以及一个置信度c,每个置信度与20个class类别的条件概率相乘,得到一个权概率向量(20维),因此每个grid cell有2个权概率向量,整个推理过程中有98个权概率向量
- 然后将98个权概率分别以颜色(class类别)和粗细(box置信度)加持,可视化即可得到如下图的98个框。经过NMS非极大值抑制之后,进而得到检测结果。

- NMS:选择权概率最高的为输出,与该输出重叠的去掉,不断重复这一过程
YOLO v8
论文:https://arxiv.org/pdf/2408.15857
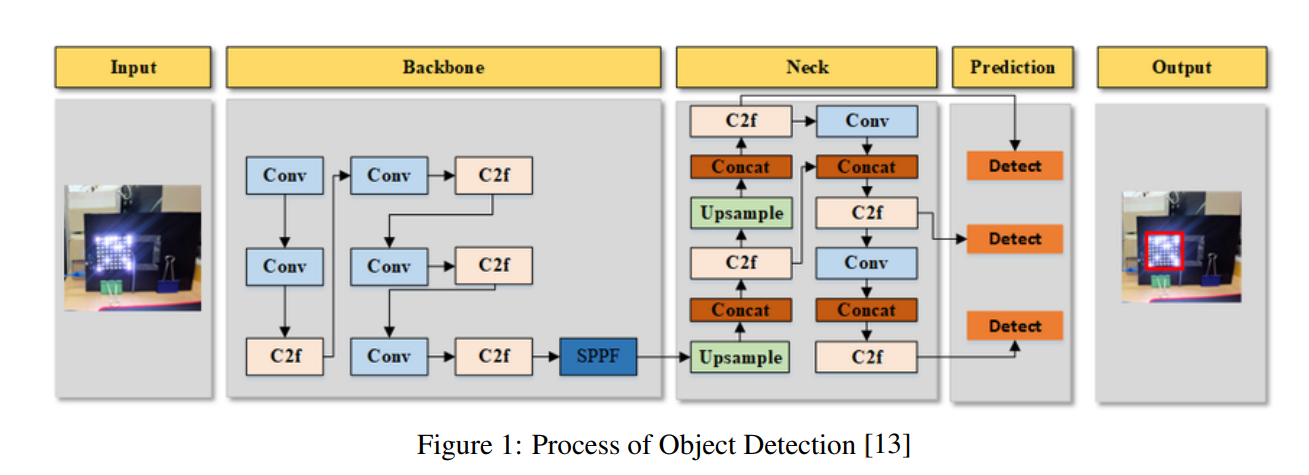
- Backbone骨干网络:提取图像的多尺度多层次特征;
- 低层特征:分辨率高,感受野小,定位比较精确,但语义弱(难以区分类别)
- 高层特征:分辨率低,感受野大,有很强的类别判别能力,但由于分辨率低,定位能力差
- Neck:融合特征,将深层的语义信息与浅层的空间信息融合起来
- FPN(Feature Pyramid Network) 自上向下把高层的语义信息传递给低层,每一层都具有语义信息,又具有分辨率,解决了传统检测对小目标不敏感的问题,提升了多尺度目标检测效果
- PAN(Path Aggregation Network) 在FPN的基础上增加了自下向上的路径,把低层的细粒度信息传递到高层,使高层具有更强的定位能力,使得语义和位置信息双向流动
- Head:输出检测结果,包括边界框x,y,w,h、目标置信度、类别分布概率
| Model | Anchor | Input | Backbone | Neck | Predict/Train |
|---|---|---|---|---|---|
| YOLOv1 | 锚框(7*7grids,2 anchors) | resize(448×448×3): 训练是224 * 224,测试是448*448; | GoogLeNet(24Conv+2FC+reshape; Dropout防止过拟合; 最后一层使用线性激活函数,其余层都使用ReLU激活函数); | 无 | IOU_Loss、nms; 一个网格只预测了2个框,并且都属于同一类; 全连接层直接预测bbox的坐标值; |
| YOLOv2 | 锚框(13*13grids,5 anchors: 通过k-means选择先验框) | resize(416* 416*3): 416/32=13,最后得到的是奇数值有实际的中心点; 在原训练的基础上又加上了(10个epoch)的448x448高分辨率样本进行微调; | Darknet-19(19Conv+5MaxPool+AvgPool+Softmax; 没有FC层,每一个卷积后都使用BN和ReLU防止过拟合(舍弃dropout); 提出passthrough层:把高分辨率特征拆分叠加大到低分辨率特征中,进行特征融合,有利于小目标的检测); | 无 | IOU_Loss、nms; 一个网络预测5个框,每个框都可以属于不同类; 预测相对于anchor box的偏移量; 多尺度训练(训练模型经过一定迭代后,输入图像尺寸变换)、联合训练机制; |
| YOLOv3 | 锚框(13* 13grids,9 anchors: 三种尺度*三种宽高比) | resize(608* 608*3) | Darknet-53(53*Conv,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,残差连接); | FPN(多尺度检测,特征融合) | IOU_Loss、nms; 多标签预测(softmax分类函数更改为logistic分类器); |
| YOLOv4 | 锚框 | resize(608* 608*3)、 Mosaic数据增强、 SAT自对抗训练数据增强 | CSPDarknet53(CSP模块:更丰富的梯度组合,同时减少计算量、 跨小批量标准化(CmBN)和Mish激活、 DropBlock正则化(随机删除一大块神经元)、 采用改进SAM注意力机制:在空间位置上添加权重); | SPP(通过最大池化将不同尺寸的输入图像变得尺寸一致)、 PANnet(修改PAN,add替换成concat) | CIOU_Loss、DIOU_nms; 自对抗训练SAT:在原始图像的基础上,添加噪音并设置权重阈值让神经网络对自身进行对抗性攻击训练; 类标签平滑:将绝对化标签进行平滑(如:[0,1]→[0.05,0.95]),即分类结果具有一定的模糊化,使得网络的抗过拟合能力增强; |
| YOLOv5 | 锚框 | resize(608* 608*3)、 Mosaic数据增强、 自适应锚框计算、 自适应图片缩放 | CSPDarknet53(CSP模块,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,Focus模块); | SPP、PAN | GIOU_Loss、DIOU_Nms; 跨网格匹配(当前网格的上、下、左、右的四个网格中找到离目标中心点最近的两个网格,再加上当前网格共三个网格进行匹配); |
| YOLOX | 无锚框 | resize(608* 608*3) | Darknet-53 | SPP、FPN | CIOU_Loss、DIOU_Nms、 Decoupled Head、 SimOTA标签分配策略; |
| YOLOv6 | 无锚框 | resize(640* 640*3) | EfficientRep Backbone(Rep算子) | SPP、Rep-PAN Neck | SIOU_Loss、DIOU_Nms、 Efficient Decoupled Head、 SimOTA标签分配策略; |
| YOLOv7 | 锚框 | resize(640* 640*3) | Darknet-53(CSP模块替换了ELAN模块; 下采样变成MP2层; 每一个卷积层后都使用BN和SiLU防止过拟合); | SPP、PAN | CIOU_Loss、DIOU_Nms、 SimOTA标签分配策略、 带辅助头的训练(通过增加训练成本,提升精度,同时不影响推理的时间); |
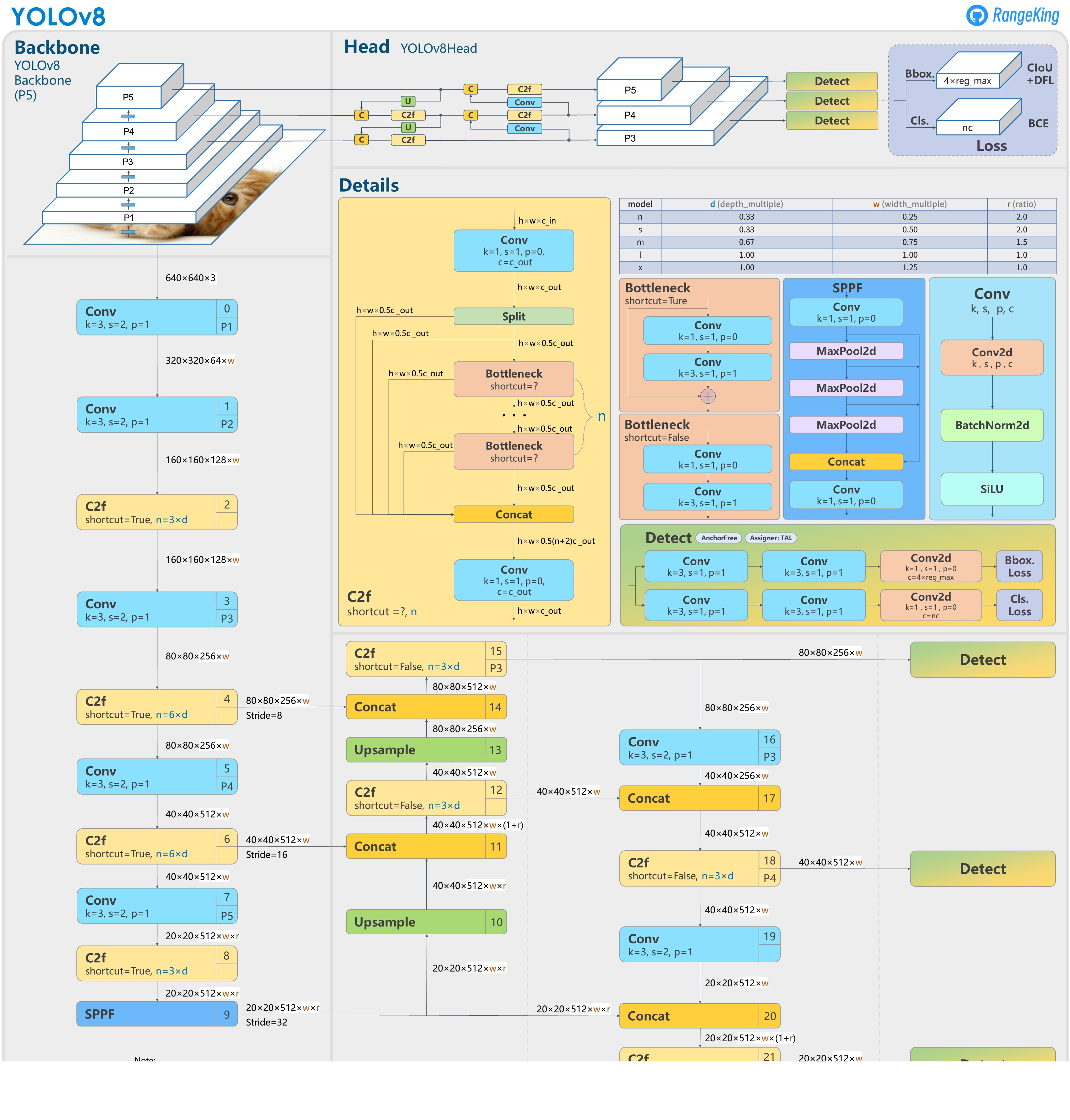
| YOLOv8 | 无锚框 | resize(640* 640*3) | Darknet-53(C3模块换成了C2F模块) | SPP、PAN | CIOU_Loss、DFL_Loss、 DIOU_Nms、 TAL标签分配策略、 Decoupled Head; |
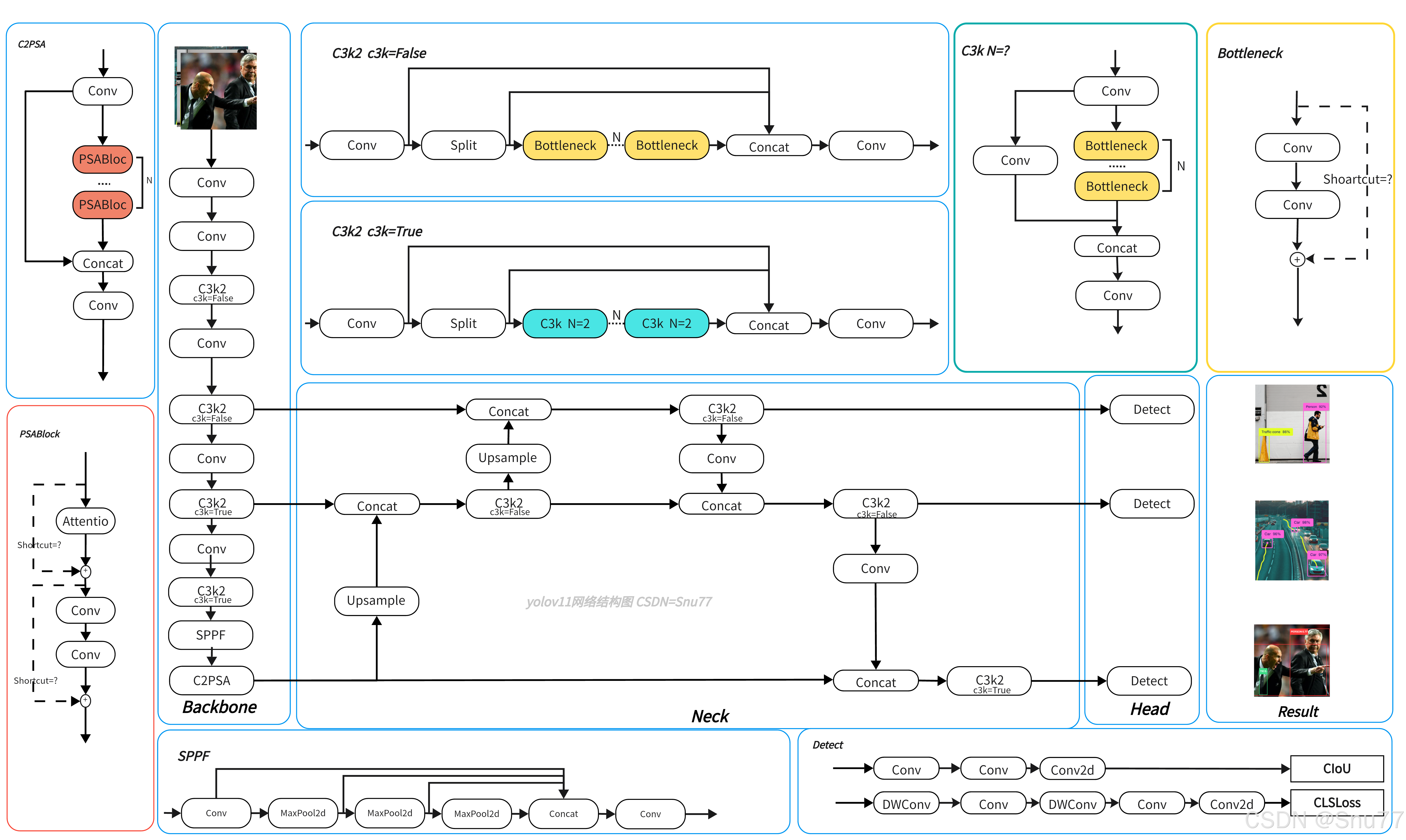
相对于v8
1.C2f -> C3k2 更轻量 2.Backbone增加了C2PSA模块 增强空间注意力,帮助模型聚焦重要或难以检测的区域