
大模型优化技术
- 大模型构建一般分为三个阶段:预训练(Pretrained),有监督微调(STF),基于人类反馈的强化学习(RLHF)
SFT - (Supervised Fine-Tuning)有监督微调
- 使用高质量的人工标注的问答数据(输入-输出对),以传统的监督学习方式对预训练好的基座模型进行微调,也就是提高大模型对一个企业专有信息的理解,增强模型在特定领域的知识。 🌟会更新模型权重
RLHF - (Reinforcement Learning from Human Feedback)基于人类反馈的强化学习
DPO(Direct Preference Optimization) 直接偏好优化
- 通过人类对比选择哪个选项更好,直接优化生成模型
- 也就是两个结果,我告诉模型一个答案好,一个答案差,让模型学着多给出好的答案
- 不需要训练奖励模型,直接利用人类偏好数据进行优化,节省成本;训练复杂度低,更稳定,调整幅度较大 🌟会更新模型权重,能对齐复杂且主观的人类偏好
PPO(Proximal Policy Optimization)
- 先训练一个奖励模型,用奖励模型指导PPO对大模型进行微调
- 训练复杂度高,调整幅度较小
RAG(Retrieval-Augmented Generation)检索增强生成
- 在模型生成答案的过程中,从一个外部知识库中实时检索相关信息,并将其作为上下文提供给模型,从而让模型能够生成事实性更强、更及时、更来源可溯的回答
- 检索是指当用户输入一个问题时,系统先将该问题在一个庞大的外部知识库(如公司文档、维基百科、最新新闻等)中进行语义检索,找到最相关的文档片段 🌟不会更新模型权重,依赖外部知识库,知识实时更新,答案可溯源,成本低
SFT微调算法的分类
全参数微调(Full Fine-Tuning)
- 更新所有参数,通常可以得到好的性能,能够适应不同任务场景;但需要比较大的计算资源而且容易出现过拟合
部分参数微调(Partial Fine-Tuning)
- 只更新部分参数,减少了计算成本,减少了过拟合风险,能够以比较小的代价取得比较好的效果,但是可能无法达到最佳性能
- 最著名的:LoRA
LoRA
https://arxiv.org/pdf/2106.09685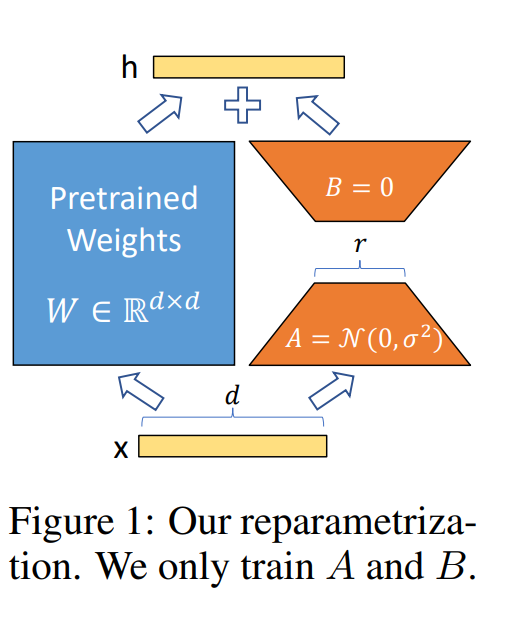
- 通过矩阵的低秩分解,将微调后原始权重的变化量变为两个存储数据量较小的矩阵,减少了参数量
- LoRA训练结束后通常需要进行权重合并
微调常见框架
Llama-Factory
- 提供了图形化界面,可以通过Web页面点点选选来配置模型、数据、参数,极大降低了使用门槛。同时也支持YAML配置文件
transformer.Trainer
- 由Hugging Face提供的高级API,与 transformers, datasets, accelerate 等库是天作之合,兼容性最好 *对 RLHF 的支持是最全面和最权威的,提供了完整的PPO(近端策略优化)训练流程实现,是很多其他框架实现RLHF的基础。 https://huggingface.co/docs/transformers/zh/main_classes/trainer
DeepSpeed
- 由微软开发的开源深度学习优化库,适合⼤规模模型训练和分布式训练,在⼤ 模型预训练和资源密集型训练的时候⽤得⽐较多
Unsloth
- 极致性能优化:核心目标非常明确——让你的微调速度更快,显存占用更少。他们通过重写内核(Kernel)等方式,实现了2-5倍的训练加速和50-80%的显存减少
- 即插即用:可以作为一个独立的库使用,也可以轻松集成到其他框架(如 TRL, LlamaFactory, Axolotl)中,为它们带来免费的加速效果
- 专注于高效微调:主要优化 LoRA 和 QLoRA 微调方式,让在消费级显卡(如RTX 3090/4090)上微调大模型成为可能
Hugging Face是什么😁
- 全球最大的预训练模型托管平台 GitHub for Models
- 全球最大的AI数据集托管平台
- 核心库:transformers 这个python库提供了数万个模型的加载使用和训练的标准化代码
- datasets: 方便地加载和处理数据集;tokenizers: 高效的文本分词工具;accelerate: 简化分布式训练(如多卡、多机)的流程;trl: 专门用于实现RLHF(如PPO训练)的库
LLaMA Factory 调参
https://blog.csdn.net/weixin_35977125/article/details/147888608
1.微调算法的选择
- 当显存 > 2*模型参数量时优先 Full Fine-Tune
- 让一个基座模型同时掌握多个不同的任务(例如,既能做文本摘要,又能做情感分析,还能做问答)时,Adapter 方法是一个很好的选择
- 单任务适配首选 LoRA:通常只需训练原模型0.1%~1% 的参数,就能达到接近全参数微调的效果;显存开销更小,合并权重后没有推理延迟
- 消费级硬件使用 QLoRA,4-bit量化使得模型显存占用减少了4倍(相比FP16)。一个7B的模型原本需要14GB,现在只需要约 3.5~4GB
2.学习率
- 恒定
- 余弦退火:让学习率随着训练过程,遵循余弦函数的形状从初始值缓慢下降到0
- 类比:就像调收音机搜台
*恒定学习率:你一直用同样的速度和力度拧旋钮,很容易拧过头错过最佳信号点,或者拧得太慢效率低下。 *余弦退火:你先快速拧动旋钮(大学习率)进行粗调,接近电台时慢慢细微调整(小学习率),直到找到最清晰的那个点- 三段式:在训练最开始的一小部分步骤(例如前5%的步数)内,学习率从0线性或渐增地上升到预设的初始学习率;在热身之后,保持学习率为一个较高的恒定值,或者使用余弦衰减等策略开始缓慢下降;在训练的最后一部分(例如最后10%-20%的步数),更激进地将学习率衰减到0(例如线性衰减或指数衰减)
- 显存波动更大(±8%)。这是因为学习率的剧烈变化会导致梯度、优化器状态等变量的变化也更剧烈,从而对显存的使用效率产生波动。但这通常是值得的,因为换来了性能的显著提升
- 三段式:在训练最开始的一小部分步骤(例如前5%的步数)内,学习率从0线性或渐增地上升到预设的初始学习率;在热身之后,保持学习率为一个较高的恒定值,或者使用余弦衰减等策略开始缓慢下降;在训练的最后一部分(例如最后10%-20%的步数),更激进地将学习率衰减到0(例如线性衰减或指数衰减)
3.Batch Size动态调整
4.混合精度训练
深度学习训练精度技术
精度配置对比表
| 模式 | 计算精度 | 梯度精度 | 参数精度 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|
| FP32 (全精度) | 32-bit | 32-bit | 32-bit | 数值稳定性最高,易于调试 | 显存占用最大,计算速度最慢 | 初始代码调试、验证想法 |
| AMP (自动混合精度) | 16/32-bit | 32-bit | 32-bit | 大幅节省显存和加速,通用性强 | 需要损失缩放防止梯度下溢 | 通用训练 (如V100, 3090, 4090显卡) |
| BF16 (Brain Float16) | b16-bit | b16-bit | 32-bit | 动态范围大,数值稳定性高 | 需要硬件支持,精度低于FP16 | A100/H100等专业显卡 |
| QLoRA (量化+LoRA) | 4-bit (反量化后计算) | 32-bit | 4/8-bit | 显存占用极低,可在消费级显卡上微调大模型 | 实现最复杂,有一定性能损失 | 低显存环境 (如在24G显卡上微调70B模型) |
QLoRA精度损失补偿配置
bash
# 命令行参数示例
--bf16 True \ # 使用BF16进行计算,利用其高稳定性
--quantization_bit 4 \ # 将模型权重量化为4-bit,主要节省手段
--quant_type nf4 \ # 使用NF4量化类型,针对神经网络权重分布优化
--double_quantization \ # 对量化常数进行二次量化,进一步压缩
--quantization_cache_dir ./quant_cache # 缓存量化结果,加速后续模型加载