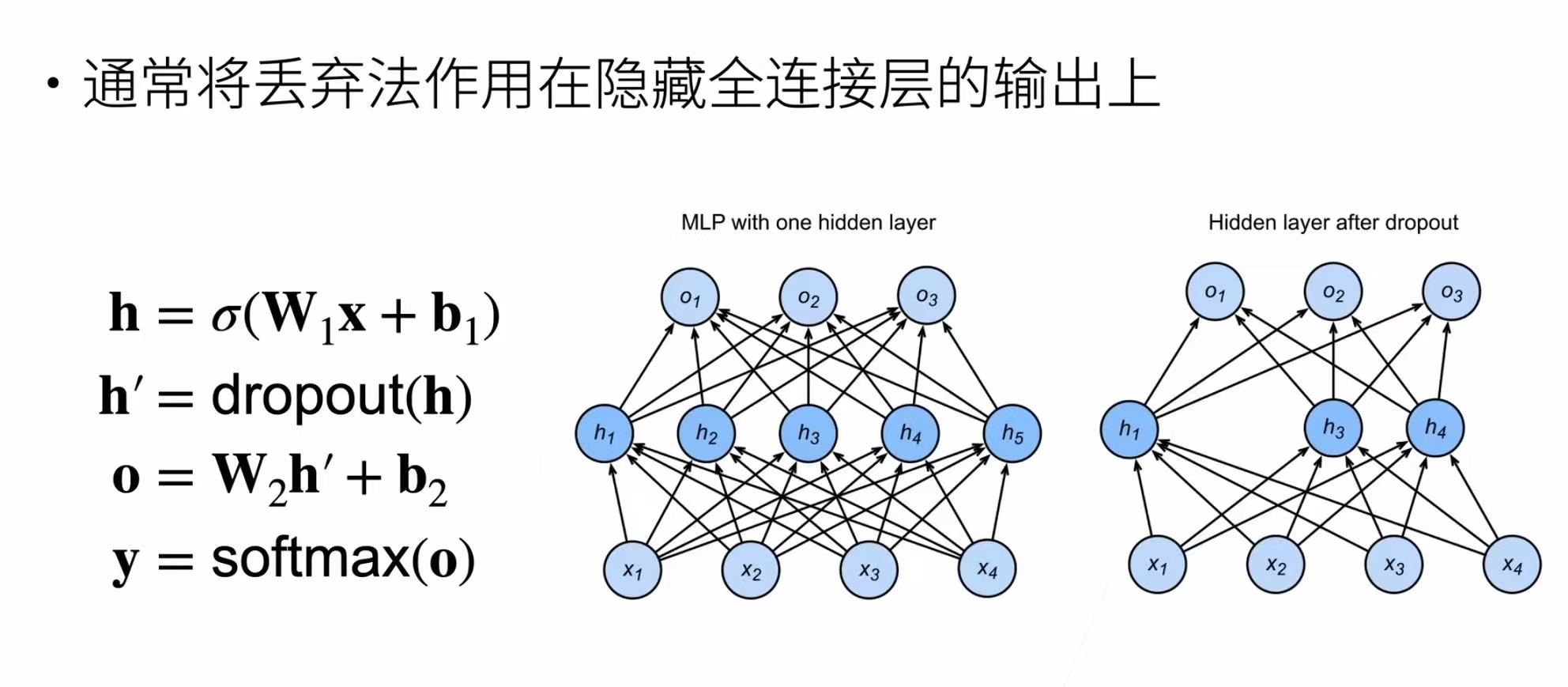
丢弃法
- 一个好的模型需要对输入数据的扰动鲁棒
- 使用有噪音的数据等价于Tikhonov法则
- 丢弃法:在层之间加入噪音
- 对加入噪音得到,我们希望
- 丢弃法对每个元素进行如下扰动
- 丢弃概率是控制模型复杂度的超参数
- 正则化是一类用于防止机器学习模型过拟合,提高泛化能力的技术
- 正则项只在训练中使用:他们影响模型参数的更新
- 丢弃法和权重衰退都是正则化
- 丢弃法是在模型训练过程中,按照一定的概率p随机地将神经网络中的某些神经元的输出设置为0,这相当于每次训练都在不同结构的子网络上进行,打破了神经元之间的复杂共适应关系,避免某些神经元过度依赖其他特定神经元
- 权重衰退,是在损失函数中加入一个与参数平方相关的正则项,在模型训练过程中,优化器不仅要最小化原始的损失函数,还要最小化正则项,这就使得参数在更新时趋向于更小的值,较小的权重意味着模型更加简单,降低过拟合风险
net = nn.Sequential()
net.add(nn.Dense(256, activation="relu"),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Dense(256, activation="relu"),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
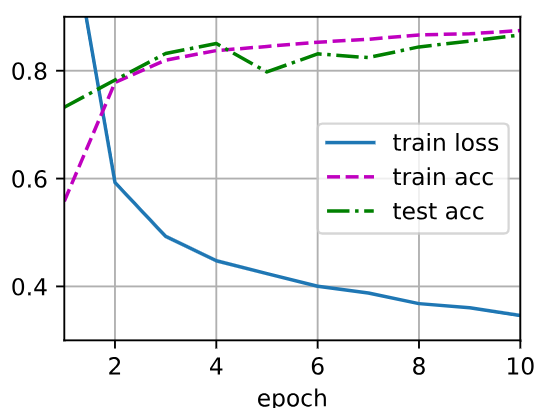
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)