解决过拟合
使用均方范数作为硬性限制
- 通过限制参数值的选择范围来控制模型容量
- 通常不限制偏移b
- 小的意味着更强的正则项
使用均方范数作为柔性限制
- 对于每个,都可以找到使得之前的目标函数等价于下面
- 超参数控制了正则项的重要程度
参数更新法则
- 计算梯度
- 时间t更新参数
\eta是学习率
通常,在深度学习中通常叫做权重衰退
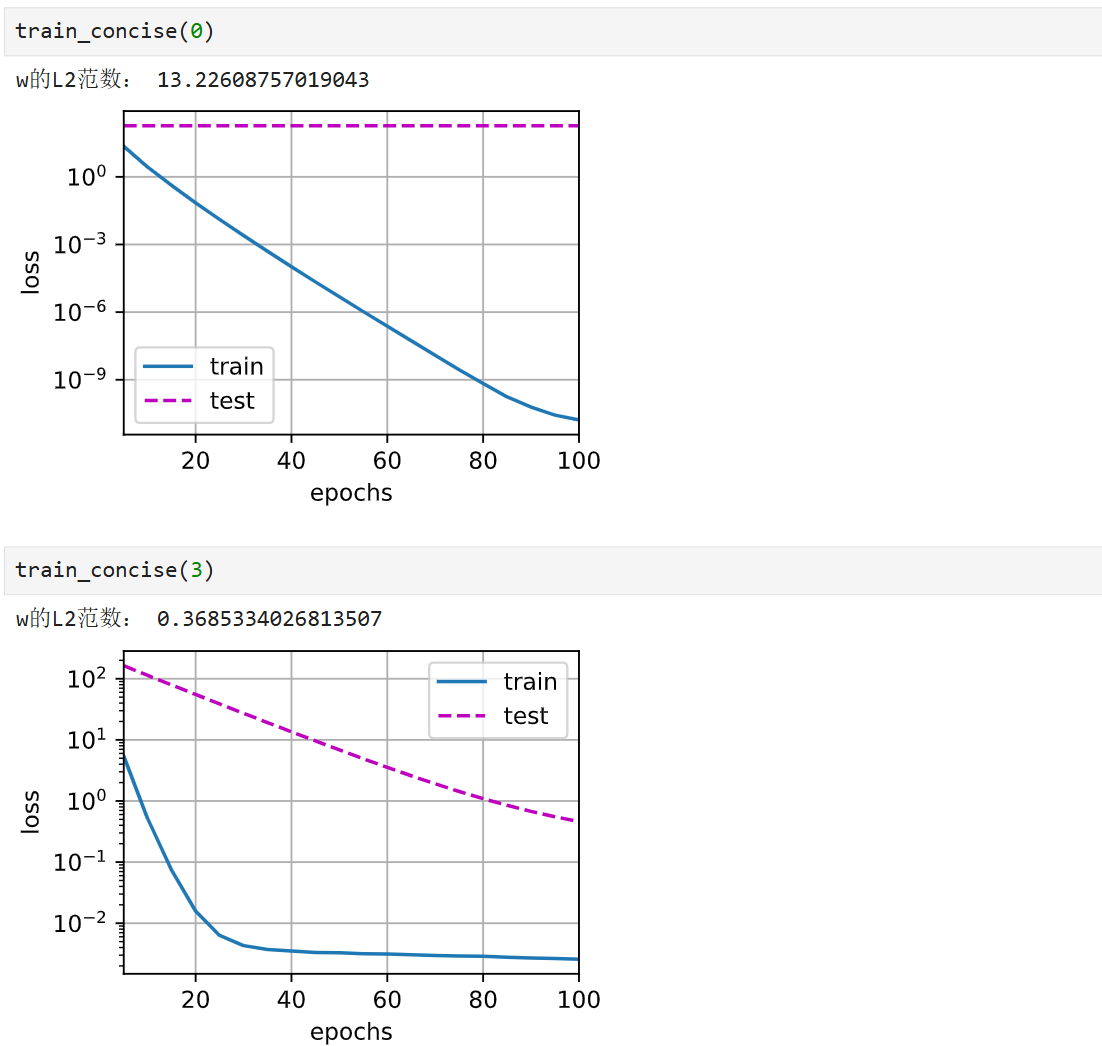
简洁实现:
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item()){"params":net[0].weight,'weight_decay': wd},给w开启权重衰减,也就是说优化器碰到这个就知道,在更新权重时,额外减去