
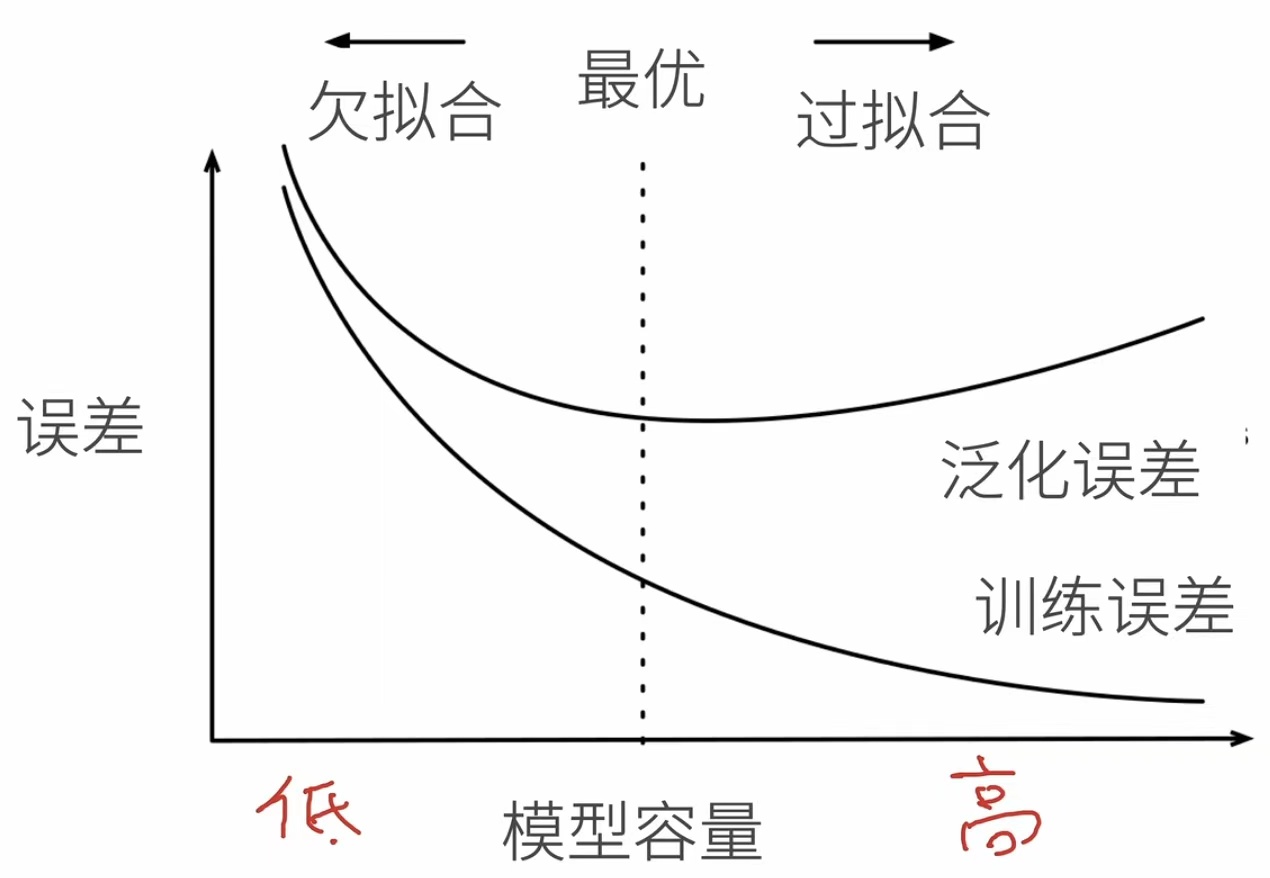
训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
验证数据集和测试数据集
- 验证数据集:一个用来评估模型好坏的数据集,例如拿出50%的训练数据,⭐不要和训练数据混在一起(模考?调整超参数,可能虚高,因为在验证数据集上调出来的精度,不一定能够代表在新数据上的泛化能力)
- 测试数据集:只用一次的数据集,例如未来的考试,出价房子的实际成交价(高考)
K-则交叉验证
- 在没有足够多数据时使用(这是常态)
- 算法:
- 将训练数据集分割成k块
- For i = 1,...,K
- 使用第i块作为验证数据集,其余作为训练数据集
- 报告K个验证误差的平均
- 常用K=5或10
参数和超参数
- 参数:模型在训练过程中自动学习和更新的变量,是模型从数据中学到的,例如w和b,数量通常很大
- 超参数:在模型训练开始前手动设置的变量,用于控制模型的结构或训练过程,例如与训练过程相关的学习率(learning rate)、批量大小(batch size)、epochs
过拟合和欠拟合
模型容量的高低,数据的简单复杂
| 简单 | 复杂 | |
|---|---|---|
| 低 | 正常 | 欠拟合 |
| 高 | 过拟合 | 正常 |
- 模型容量:拟合各种函数的能力,低容量的模型难以拟合训练数据,高容量的模型可以记住所有的训练数据
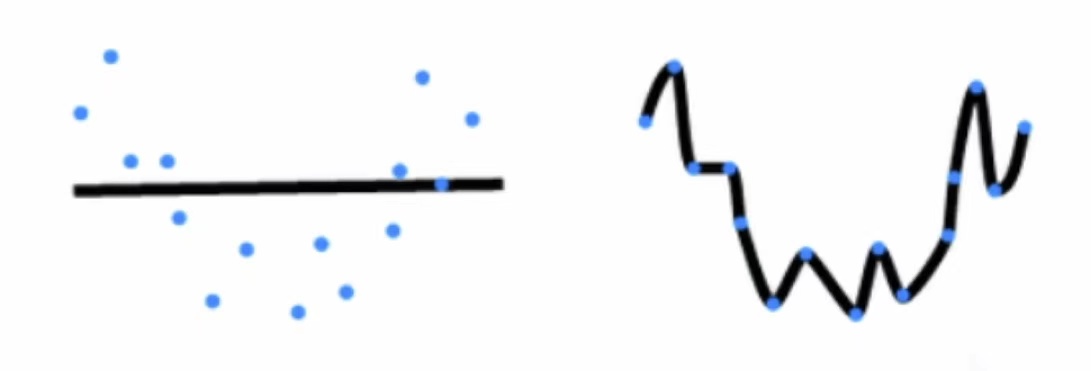
给定一个模型种类,有两个主要因素:参数个数,参数值的选择范围
VC维
- 统计学习理论的一个核心思想
- 对于一个分类模型,VC等于一个最大的数据集的大小,不管如何给定标号,都存在一个模型对它进行完美分类,表示一个函数集能够打散的最大样本数目
- 例如:在二维平面上,线性分类器的VC维是3
- 可以衡量训练误差和泛化误差之间的间隔,但在深度学习很少使用
数据复杂度
- 样本个数
- 每个样本的元素数
- 时间、空间结构
- 多样性