
什么是目标检测
- 感兴趣的目标
- 定位
- 识别
目标检测数据集
- 输入
- 输出:带有目标的标注
衡量数据集的好坏:
- 数据集内容的数量
- 数据集能充分反应实际场景
- 标注数据集的质量
VOC数据集目录结构
tree
-VOCdevkit
|-VOC2007
|-Annotations(所有对应的图片的标注,xml文件⭐)
|-ImageSets
|-JPENGImages(存放图片⭐)
|-SementationClass(图像分割,同一种类别用相同颜色进行标注)
|-SementationObject(图像分割,每个物体用不同颜色标注)xml
<segmented>0</segmented>表示该图片没有进行分割
xml
<object>
<name>cat</name>
<pose>Right</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>231</xmin>
<ymin>88</ymin>
<xmax>483</xmax>
<ymax>256</ymax>
</bndbox>
</object>- pose标签是拍摄角度,truncated是判断这张图片有没有被完整标注,0表示被完整标注,difficult是0表示是确定这个目标类别不困难
- bndbox标签⭐
- 标注:x从左往右越来越大,y从上到下越来越大,标注的是左上角和右下角
CoCo数据集
- 训练数据集,验证数据集,测试数据集
- 主要是2014 2017
|-annotations_trainval2017
|-annotayions
|-captions_train2017.json(看图说话)
|-captions_val2017.json
|-instance_train2017.json(目标检测的标注)⭐
|-instance_val2017.json
|-person_keypoint_train2017.json(对人体关键节点的标注)
|-person_keypoint_val2017.json
|-train2017(训练的图片)
|-val2017(验证的图片)instance_train2017.json
|-info
|-licenses
|-image(文件名⭐、地址、宽高、时间、id⭐)
|-annotation
|-segmentation(图像分割)
|-area
|-iscrowd
|-image_id⭐
|-bbox(框选的坐标)⭐
|-category_id
|-id(唯一标识)
|-categories- 如果我们想找到00003895.jpg的所有标注,那么我们需要找出标注信息中image_id=3895的所有标注
- bbox中的数字分别代表 xmin,ymin,width,height
YOLO
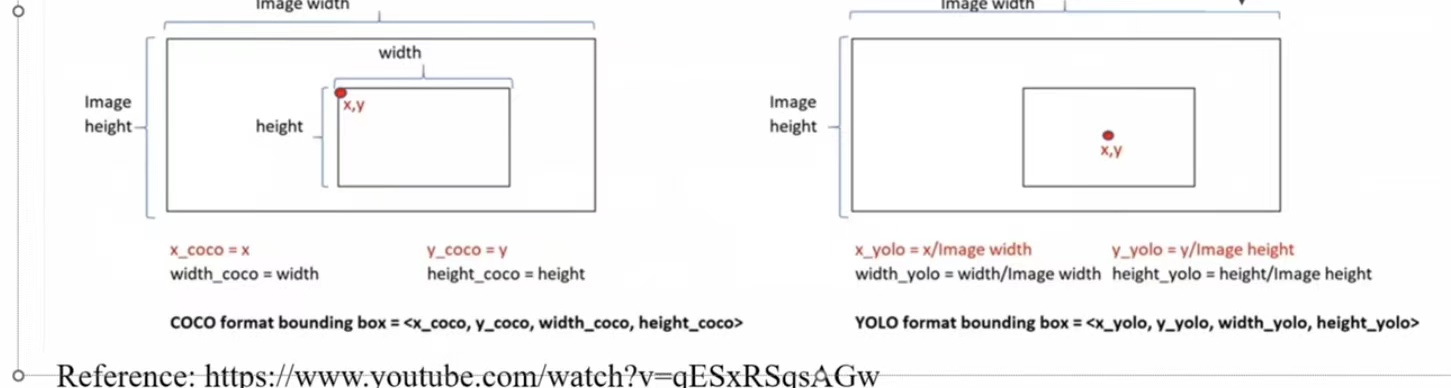
- yolo做了归一化,关注的是中心点
标注自己的数据集
- 采集自己的数据集
- 明确任务 检测不带头盔的摩托车驾驶员,并检测摸通常车牌号
- 感兴趣的目标:不带头盔(class_id = 0)、摩托车(class_id = 1)、车牌号(class_id =2)

class.txt
no helmet
motor
number(摩托车车牌)
...- 利用标注工具来标注数据集
- Labellmg https://github.com/HumanSignal/labelImg
- LabelStudio 协同
- Labelme https://github.com/wkentaro/labelme
Labelme演示
目录:
|-自定义数据集
|-train
|—imges
|-labels
|-val
|-classes
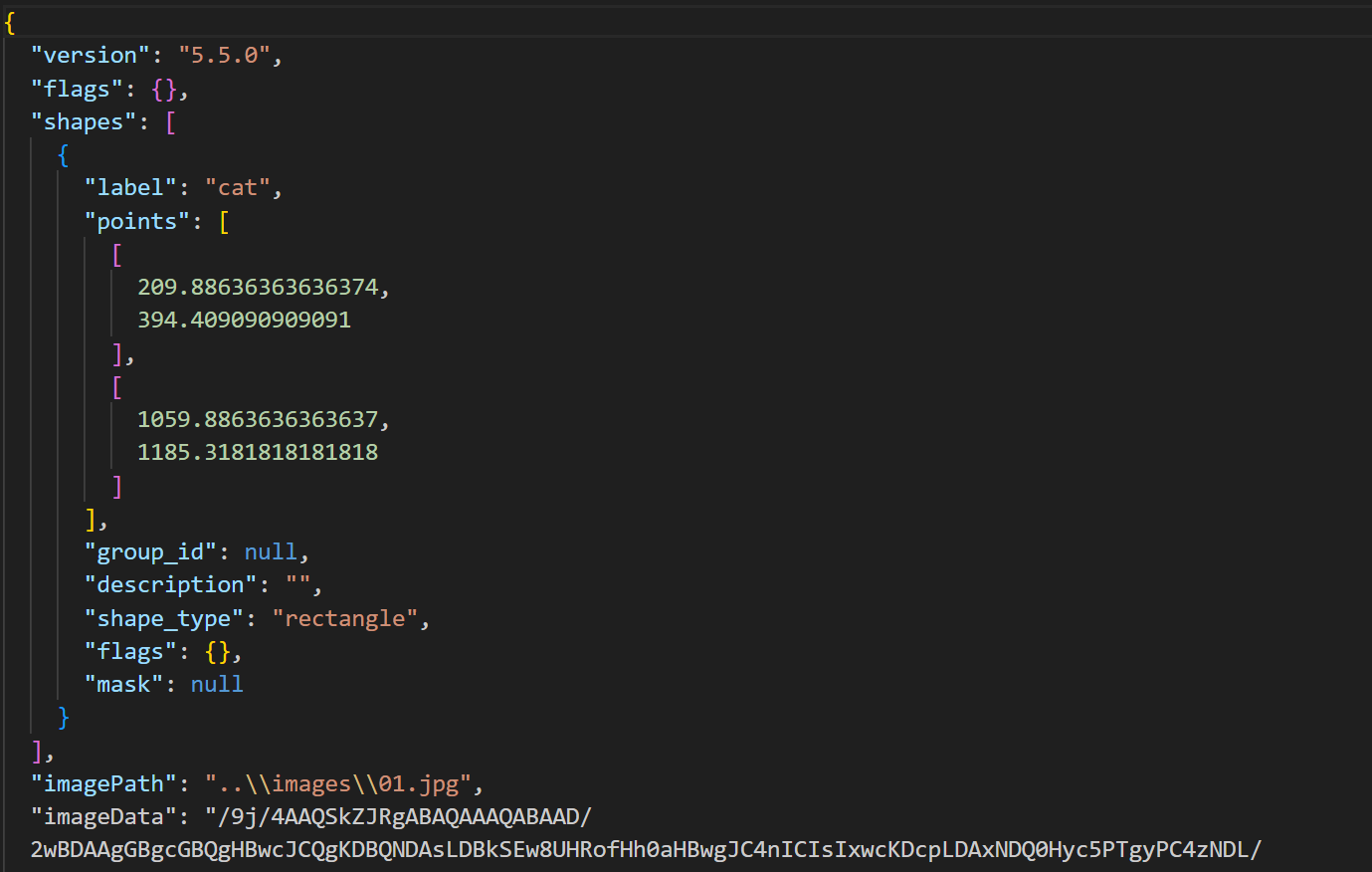
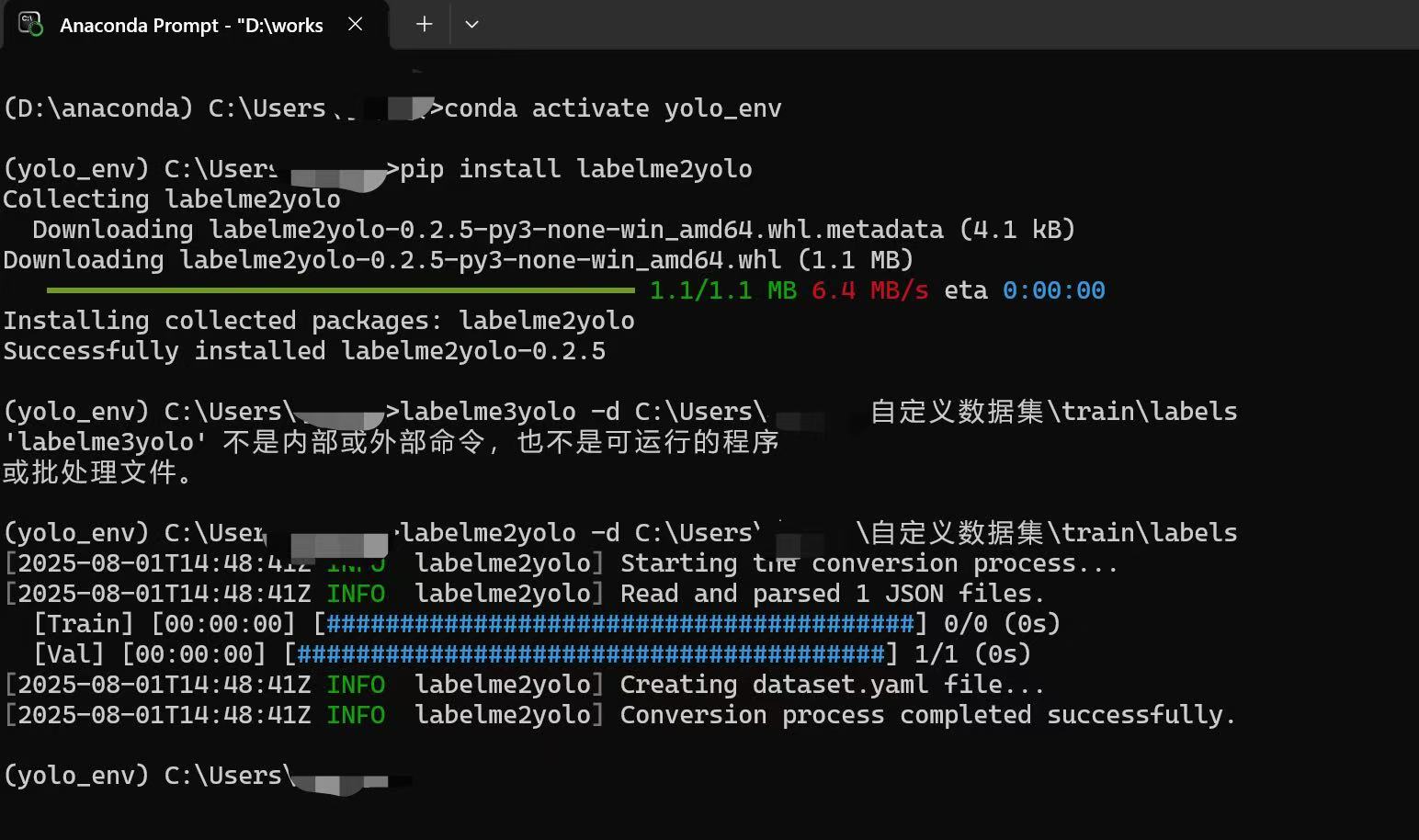
- 输出是json格式,Labelme2YOLO可以转换
加载数据集
https://docs.pytorch.org/tutorials/beginner/basics/data_tutorial.html 加载VOC格式的数据:
import os
from PIL import Image
import xmltodict
import torch
from torch.utils.data import Dataset
class VOCDataset(Dataset):
def __init__(self,image_folder,label_folder,transform,label_transform):
self.image_folder = image_folder
self.label_folder = label_folder
self.transform = transform
self.label_transform = label_transform
self.img_names = os.listdir(self.image_folder)
self.class_list = ["no helmet","motor","number","with helmet"]
def __len__(self):
return len(self.img_names)
def __getitem__(self, index):
img_name = self.img_names[index]
img_path = os.path.join(self.image_folder,img_name)
image = Image.open(img_path).convert("RGB")
label_name = img_name.split(".")[0] + ".xml"
label_path = os.path.join(self.label_folder,label_name)
with open(label_path,"r",encoding="utf-8") as f:
label_content = f.read()
label_dict = xmltodict.parse(label_content)
objects = label_dict["annotation"]["object"]
target = []
for object in objects:
object_name = object["name"]
object_class_id = self.class_list.index(object_name)
object_xmax = float(["bndbox"]["xmax"])
object_ymax = float(["bndbox"]["ymax"])
object_xmin = float(["bndbox"]["xmin"])
object_ymin = float(["bndbox"]["ymin"])
target.extend([object_class_id,object_xmax,object_ymax,object_xmin,object_ymin])
target = torch.tensor(target)
if self.transform is not None:
image = self.transform(image)
return image,target用yolov8训练自己的安全帽模型
- 首先下载数据集,自己做的话太麻烦了,直接下载了yolo格式的,直接就能用
- 然后写yaml文件,例如:
train: C:\Users\Li\Downloads\archive\css-data\train\images\
val: C:\Users\Li\Downloads\archive\css-data\valid\images\
test: C:\Users\Li\Downloads\archive\css-data\test\images\
nc: 10
names: [Hardhat,Mask,NO-Hardhat,No-Mask,No-Safety Vest,Person,Safety Cone,SafetyVest,machinery,vehicle]- 然后创建一个虚拟的干净python环境,下载Ultralytics,编写train.py文件,例如
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data='safehat.yaml',epochs=100)
model.val()- 最后进入虚拟环境,运行python train.py文件,开始训练